JJUG CCC 2024 Fall で スポンサー登壇しました
1週間経ってしまったけど書かなきゃ終わらない気がしたので書きます。
初めてJJUG CCCに参加したのが確か2016 Fall の時だったのでそれから8年経って初登壇しました。スポンサー枠ですが。
内容としては 去年9月にクレディセゾンに入社してから担当していた Netアンサーが、今年 大きな移行・更改を行ったのでどういう点を変更したのかっていうことを紹介した内容になります。
いざ書いてみたら色々と話したいことが増えていったこともあり、全体的に浅めな説明にはなってしまったかなと思います。JJUG なので Struts1 から Spring Boot3への移行の話を中心にしたかったので、フロントエンドやインフラ・CI/CD周りはこんな感じですって内容に抑えました。
スポンサー登壇までの歩み
ことの発端は、前回 2024 Spring に参加したときに会場が狭くて聴きたかったセッションが満席で入れなかったりしたのでアンケートにその辺をコメントしたのですが後日「会社に打診してスポンサーになれば広い会場になるかも」的なツイートを見かけたので、ダメ元で テクノロジーセンター内の雑談チャンネルに投げたら翌日には動き始めていましたw (この辺は一緒に登壇した CTO小野さんの資料を見てください)
この件、社内でもあまり話したことは無いのですが、個人的にはSlackで放流したら前向きには検討してくれそうな予感はしていました。というのも 社内にはJJUGにゆかりがある人が結構いたためです。まぁダメだったとしても「会社に打診はしたけどダメでした」とは言えるので、放流するだけ放流しようかなと。
で、スポンサーになるのがOKとなった後は、JJUGのスポンサープロジェクトなるチャンネルが立ち上がり、小野さんに登壇してもらうことも決まり、1つか2つ事例発表も入れようとなってその候補者を募集するって所まではすぐに決まりました。 ただ登壇希望者が現れない状況が続き、自分にも打診はあったのですが、今後、同じような企画をした時に、言い出した人が何かをしないといけないみたいな空気にはさせたく無いなと思い様子を見ていました。
ですが、JJUG CCC でいつかは登壇してみたいって思いながら8年も経過していて登壇する機会を失っていた感があったのと、StrutsからSpringへの移行事例って需要あるかもって話を社内でも聞いているうちに誰も手を挙げないなら自分話しますって手を挙げたって感じでした。
ちなみにこの流れに乗る感じで公募でも3名採択されたことで、内部でもJJUG CCCに向けてお祭り感は出るようになりました。 個人的には裏の目的として自分のチームの若い人達やJJUG CCCに参加したことがない人に参加してもらいたいと思っていたのでこれによって参加しますって人が増えたのも良かった。
当日のこと
正直、緊張というか不安というか、なんか落ち着かない感じでした。 他の方のセッションに参加しても Xでの反応が気になったり、事前に聞いてはいたけど会場のスクリーンが想像以上に小さめで資料が見づらいんじゃないかとか考えていて、あまり他の人の発表が頭に入らなかった気がします。この辺は反省点ですね。
そして自分たちの時間になりまずは前半パートとして小野さんから話して頂きましたが、改めてこの人凄いなって思いましたね。登壇の時の内容は別の機会に何度か聴いてますし今回の資料も事前に共有させて頂いていたのですが、自己紹介のページだけでこんなに豊富で面白い話が出来ることとか自己紹介だけで結構時間を使っていたので20分で終わるのかなとか気になったのですが特に急ぐ感じでもなく予定通り20分で話をまとめた所とか。それに前から参加している方々の表情を見たりしてましたが、みなさん小野さんの話に聞き入っているって感じなのがとても伝わりました。 こんな面白くてみんな聞き入ってる凄い話の後に自分が話すのかって直前になって手を挙げたことへのプレッシャーを感じていました。
それで自分の番が来て、なんとか20分でまとめ上げることができました。 リハーサルしていた時は結構ゆっくり目に話してちょうど良い位だったのですが、本番では小野さんの話の勢いに乗る感じで 台本にないことも含めて少し早口で話して20分少し過ぎちゃう感じだったかなと思います。 間をとることも忘れていたので途中 息切れしたことに自分でも気がつきました。
まだアンケートの結果などは見ていませんが、ツイートや小野さん含め社内の人達からは良い評価を頂けていたようですし、その前の同僚のセッションも含めてクレディセゾン テクノロジーセンターの存在感を見せられた場になったようで良かったです。 あと 登壇後や会場の廊下で 自分は以前から知っていた方々に声かけられて質問されたりしたのですが 聞いてくれていたんだと知って嬉しかったです。
登壇内容の補足
登壇のテーマがモダナイゼーションということでアーキテクチャを変えたことを説明したわけですがそれらの選定理由を登壇時に説明していなかったので、登壇後の質問などで聞かれましたので、この場で補足しようと思います。
その前に大前提
登壇で技術選定について話さなかった理由というか言い訳ですが、入社した2023年9月の時点でプロジェクトは始まっており主要な選定は終わっており自分としてイニシアチブというか選定に関わっていなかったので敢えて避けたって点があります。 入社後にこれは変えた方が良いって感じた所は自分が主導して変更したものも幾つかはありますが。
ただAWS移行後は モダンアプリ側のチームリーダーになり、保守運用を通してこのアーキテクチャにして良い点と改善点も色々出てきていますし、この11月からはクラシック側も含めて Netアンサー開発チームの全体を見るようになったので、これからは少しずつ自分の判断で変える部分も出てくると思います。
ということで、ここでは選定理由だけでなくて運用してみて気づいた点も含めて話します。
Struts1 からの移行先として Spring Boot3 以外の JavaのWebフレームワークにしなかった理由はあるか?
単純にチームメンバー的にも社内的にも Springには慣れているメンバーだったからというのが理由になります。内製化チームとしては他にもSpring Boot利用したシステムを開発していたので、Spring ありきで検討していた所はあります。 JakartaEEなどの他のJavaのWebフレームワークを評価して決めたとかでは無かったです。
ただ、フロントエンドについてはUXの視点からもSPAにしたいって考えていたので、JavascriptのWebフレームワークには変える想定で進んでおりこれについては後述します。
EKS (Kubernetes) を採用した理由は? ECSにしなかった理由は
これは同じ課でNetアンサーの前にモダナイゼーションを進めていた オープンGWという社内向けAPIサービスでEKSを利用し、それをベースにAWSに移行したことが主な理由になります。 オープンGWがEKSを採用した背景については、以前 JAWS-UGで話した内容がYoutubeに公開されているのでそちらをご覧ください。(37分頃から)
尚、登壇時には話していませんが内製化チーム側のモダンサービスのバックエンドは Spring Bootによる業務APIサービス以外に、PDFファイルを生成するNodeJSのサービスなど幾つかのサービスに分割しています。 そしてAWS移行当初は ベンダーさん保守のEC2(現クラシック) と 内製化チーム担当のEKS(モダン)に明確に分かれていたので、AWSのALBによってEC2とモダンの2系統だけをルーティングするようにして、モダン内部のサービス分散はEKS(k8s)でIngress Controller を用意することでモダン自身でコントロール出来るのもメリットでした。
ただEC2もクラシックといてEKSでコンテナ化したので このメリットもあまり意味が無くなってくるので、ECSでよりシンプルな構成にする可能性も今後あるかもしれません。
Svelteを採用した理由は?
ここも大きな理由はなくて自分たちのスキルを考えた時にあっているのは何か?という視点で検討した結果となります。フロントエンド(HTML + CSS + JS) については Thymleaf か JSP に慣れていたので標準的なHTMLの構文には慣れているメンバーがほとんどだったので、Svelte か Vue のどちらかとなり、「公式のチュートリアルの充実さ」や「テクノロジーセンターでSvelteに詳しくSvelte推しな人がいる」という点でSvelteを選択しました。(仮想DOMがー。とかコンパイルがー。とかの技術的な観点はあまり参考にしませんでした。)
ちなみに Vueで開発しているシステムもありますし、NetアンサーチームでもJSフレームワークを使ったフロントエンド開発が初めての人には Reactの公式ドキュメントの「Reactの流儀」などを見てコンポーネント構造の勘所を理解してもらったりもしています。 ReactやVueと比較したときのSveltのエコシステムが充実していないので参考にできるものは参考にしています。
なお、先日 Svelte5 が出ましたが、Netアンサーも早く対応したいのですがとある理由で少し保留中の状態だったりします。
AWS CDK を Javaで書いた理由は?
これもEKSと同様で、オープンGWのインフラ開発期間の都合で慣れていたJavaを使っていてその流れというか流用できる部分が多かったので、NetアンサーのCDKもJavaで書いています。
Javaで書いて困っている点は特段ありませんが、強いてありませんがCDKを実行する前に mvn install を実行するのですがこれに少し時間が掛かることでしょうか? 今の所、書き直す予定はありませんが、EKSのクラスタアップデートや改善と合わせて Typescriptなど別の言語に書き直すかもしれません。
まとめ
JJUG CCC 2024 Fall における クレディセゾンのスポンサープロジェクトは これで完了になります。(他にもブログを出すメンバーがいると思いますが。) 思えば自分の一言がきっかけで 当日は5人の登壇者の中で自分が一番最後に話したので、自分で始まり自分で終わったなと気がつきました。
今回スポンサーセッションではありますが、初めてJJUG CCC に登壇して準備からかなり大変でしたが終わってみてやって良かったなと思います。 登壇へのハードルも下がったので、今度は何か話したいなと思うネタがあったら CfPを出してみようかな
最後に JJUG CCC 2024 Fall に参加して クレディセゾンのセッションを聴いた方々や 参加はできなかったけど 登壇資料を見て興味を持った方がいらっしゃいましたら、カジュアル面談を受け付けています。 いますぐの転職を考えていなくてもテクノロジーセンターがどんな所でどんな人たちがいるのかを知ることができると思いますので、ぜひお話ししましょう!
病気から1年経ったし仕事も変わったので今更去年を振り返る
去年の2023/1/12 に脳梗塞を発症して1年経ちました。先日MRI検査を受け特に問題も無く経過も順調だったので、今年も1月は半分過ぎちゃったけど去年1年を振り返りたいと思います。
病気のこと
入院中から退院、復職までの話は4月末に書いたのでその後の話をします
5月以降も左半身の麻痺からの回復具合は良好で仕事や日常の生活で困っていることは全く無いと言っても差し支えない状態です。人と会っても多分麻痺しているってのはわからないと思います。
ウォーキングやジョギングも週5日のペースで続けられています。最近は週一で5kmを30分切るペースで走ったりもしています。冬は寒くて早朝ランニングができないのが残念。
8月には病院と警察の許可をもらい自動車の運転を再開しました。近場や県内の移動ばかりで長距離は控えているけど今まで通りの運転ができています
食生活では塩分量に気にするようになりラーメンとかスープ、漬物などは出来るだけ食べないようになった。特に以前は間食や夜食でカップ麺を食べることもそれなりにあったけど、去年は大晦日の夜にカップ蕎麦を食べただけでした。お酒も一切飲まなかったし飲むことはもう無いと思う。
ただ再発の不安は常に抱えていて、毎日ちょっとしたことで気持ちが不安定になりがち。年末年始は有名人などが脳卒中や心筋梗塞等が原因の訃報を目にすることが多かった気がするし他人事のようには思えなかった。
仕事のこと
実は4ヶ月前の2023年の9月に転職しました。
前職は復職後に短時間勤務とか業務負荷など沢山配慮して頂けたことに感謝しているのですが、休職中に会社のトップが交代したのをキッカケに開発部門全体として仕事のやり方が変わり始めていたこと、更に10月から開発組織や体制も大きく変更することが決まりこの変化に付いて行くかどうか考えた末、辞めることにしました。
現在は金融系の事業会社で、システムの内製開発を行う部門に配属しており、所属チームやCTO、人事との採用面談でも自分の病気のことを理解してもらった上で無理のない範囲でお仕事させてもらっています。
配属先ではユーザー向けサービスを段階的にマイグレーションするプロジェクトに関わっており、フロントエンドはTypeScript/Svelte、バックエンドはJava/Spring と自分の得意な領域が生かせています。
今年の抱負
- 健康第一は変わらず
- 去年一年続けられたことを今年も継続する
- オフラインで勉強会に参加したい
- オンラインだと集中して聴けなくなった
- 現職で週一でオフィスに行くようにしたら、雑談とか人と直接話すことの良さも再確認できたし
- 猫を迎え入れたい
- 去年・一昨年と我が家的には良い出来事が少なかったので雰囲気を変えたい
それでは今年もよろしくお願いします
病気で3ヶ月間休職して復職するまでのこと
今年の1月上旬に 脳梗塞を発症し左腕と左足に軽い麻痺が残りました。先日復職したのでこの3ヶ月のことをまとめてみました。 これは自分の経験に過ぎないので、もし似たような身体の不調があっても参考にするのではなくとにかく救急車を呼んで脳神経外科に診てもらうことをお勧めします。
発症前の健康状態
- 年齢:44歳
- 体重:66kg
- 標準体重だがどちらかといえば痩せ型
- 持病
- その他生活習慣
- 運動:コロナ禍になってからの3年間ほとんど運動していなかった。保育園のお迎えで往復2000歩位歩く程度
- 飲酒・喫煙:ほぼ毎日350mlのビールを飲んでた。喫煙はなし
- 食事:塩分とかは気にしてなかった。ラーメンとかはスープは全部飲まないとかはしていた
- 睡眠:平均5,6時間
2023年1月12日 13時過ぎ
- 左腕と左足に力が入らなくなる
- 左腕は特に肘と肩に力が入らず腕が上げられなかった
- 左足は膝に力が入らず立てなかった。壁や手すりに寄りかかって右足で移動してた
- 左手の指はキーボードを打つなど普通に動かせた
- 顔面は何でもなかったが喋ると左側の舌を噛みそうだった
- 身体の不調や頭痛のような予兆は午前中も前日までも無かった
- 救急車を呼んで病院に搬送される
- この時に脳外科が無い病院への搬送を選んだのは失敗だった
- 家に自分一人だったので判断が鈍っていたのと病院に3件断られてしまっていたので「診てもらえるなら」とお願いしてしまった
- 後述の病院で言われたのだが発症後4~6時間以内だと特別な治療ができて後遺症もひどくならなかったかもしれなかった
13時30分頃
- 病院でCTを撮り特に異常は発見されなかった
- 「しばらくしても回復しなかったら脳外科のある病院で診てもらう」ように言われて15時頃に帰宅した
21時頃
- 少し寝たり安静にしていたが回復しないので救急車を呼ぶ
- 24時過ぎに3つほど離れた市の病院に受け入れてもらった
- 受け入れ先が見つかるまで2時間と移動で1時間ほど掛かる結果となった
- 夜間だったのに加え、自宅で身体を必要以上に温めており体温が37度を超えていたのも影響した
24時過ぎ
入院〜2月上旬(急性期)
- 最初の1週間、専門病棟で点滴・投薬治療
- トイレや検査などの必要最低限の移動以外はベッドで安静
- リハビリも入院初日から初まり手や足を上げたり指を動かす練習を行なった
- 2週目から一般病棟に移る
- 3週目から病室の歩行が許可された
- 左手も少し動くようになり、お茶碗を持ったりボタンの留め外し、靴紐を結んだりできるようになった
- 4週目を過ぎると病棟内の移動も許された
- リハビリでは階段の昇り降り、病院の外周を歩いたりした
痛風に掛かった
- 入院して3日位経って左の親指の付け根が痛くなり腫れるようになった
- 痛風と診断され痛み止めと尿酸値を下げる薬を処方された
- その後2ヶ月間に親指の付け根と左足の内側のくるぶしに2回ずつ痛みが出た
- 尿酸値を下げる薬は継続中で数値も標準値に戻って以降は問題なし
2月上旬〜3月上旬(回復期)
- 自宅から比較的近い病院に転院しリハビリを続けた
- 3月に子供の卒園式があったのでそれに間に合うスケジュールでリハビリ計画を建ててもらった
- 当初から自主トレメニューも組んでもらった
- 転院直後はタイピングするとすぐに肩が痛くなったり歩行も5分ほどで足が痛くなって歩けなかったが、退院時には2〜30分くらい続けても平気になった
- 転院した時にラダートレーニングをしている患者さんを見かけ「自分もできるようになるかな」って考えていたけど、退院1週間前くらいにできたのは嬉しかった
- 予定通り卒園式前日に退院し卒園式と4月の入学式にも出席することができた
入院中にめまいが発生
- 転院して10日位経った日の朝から頭を傾けると目が回る症状が発生した
- 歩けないほど酷く目が回った
- 1〜2分ほどで直るがまた頭を動かすと発生することが続いた
- 「良性発作性頭位めまい症」と診断された
- 検査したところ脳に変わったことは見られなかった
- 3日後には強いめまいは起こらなくなった
- 今でもフラッとするめまいは起こることはある
- これ以降 メンタル面がやられ今でも続いている
- 身体のちょっとしたことが気になってしまう
- ひどい時は眠れなくなることもあった
- 首のこりが酷くなりそこから来る軽い頭痛や右左関係なく手や足が痺れることが増えた
- 退院後も医者に相談したが脳の問題ではないようなのであまり気にしないようにと言われた
退院〜4月上旬:復職するまで
- 普段の生活や作業に慣れるため1ヶ月は自宅でリハビリを続けた
- 毎日、6000歩を歩くようにした
- ジョギングも1-2km行うようにした
- 普段の移動で足が痛くなることは無くなった
- 自転車も乗れるが極力歩くようにしている
- 会社に復帰の相談をした
- 病気の後遺症よりも前述のめまいの影響の方が不安だったのでフルタイムではなく10-15時の短時間勤務から始めるようにしてもらった(とりあえず2ヶ月間)
- 4/13から復帰して2週間が経過した。
- ちなみに退院直後は子供たちと左手で指相撲すると普通に負けるレベルだった
現在
- 順調でこれまで通りの生活ができている
- 元々の8割位には回復しており生活に困ることはない
- 走るのもスピードはともかくできるし、階段の昇り降りも普通にできる
- 先日は一人でカレーも作れた
- タイピングも気にならない
- ルービックキューブも30秒前後で解けるようになった(病気になる前は20秒)
- 車の運転は警察の評価や病院の診断が必要で早ければ7月位から許可がもらえそう
- 短時間勤務もちょうど良い
- 4時間なので物足りない時もあるけど疲れる時もある
- その日の目標も無理のない程度に設定し達成できるようになった
- 無駄だと思う会議や業務も辞退するようにした
- 休職したことで自分が担当していた仕事が全て別の人に割り振られていたので自分がいなくても良くなった感もある
- 残業などの長時間勤務は避けたいので、短時間勤務の期間が終わった後が不安
- 時間に縛られない働き方ができたら良いなぁ
- 生活習慣はかなり変わった
- 再発が一番怖い
- 脳梗塞の再発率は決して低くはない
- 今回も予兆が無かったわけだしいつ発症するかわからないのと発症した時の後遺症がどの位酷くなるかが一番不安
- 加えてたまに出るめまいでメンタルが弱る
- 少なくともあと20年位は無事に働きたい
- なので体調とメンタル優先で生活習慣を改善し続けたい
休職中に勉強したこと
実はこれが一番描きたかったことかも。入院中や退院後に個人的に気になっていたことに挑戦していた。 現職では フロントもバックエンドも全てTypescriptなのだが、バックエンドはJava + Spring で開発するのがやっぱり好きだなって再確認した。
Spring for GraphQL を試してみた
現職でもGraphQL(Apollo)を使っているのだが辛いことばかりでメリットがイマイチわからなかったのでSpringの公式ドキュメントを参考にして動かしてみた。
おかげで、@SchemaMapping と @BatchMappingのメリットが理解できたし、SpringならControllerクラスを置き換えればREST APIとの互換性も取れそうだし、Spring Securityも利用した権限制御もできるので結構メリットがあるなと感じた。
Spring MVC のREST APIテストコードの書き方についてまとめた
去年から書こうと思って忘れていたので書いた。クライアントにWebTestClientを使ってテストコードを書いてみた
Spring Actuator と Grafana Stack を使ってみた
この辺のツールについて詳しく無かったので Spring Bootアプリのメトリクスを収集してGrafanaStackで可視化するまでを試してみた。 Metrics, Trace, Log の収集と連携を行えるようにすることで Observabilityの良さを少し実感できたと思う。
#### フロントエンドの復習
逆にフロントエンドについては、エコシステムの良さが気に入っているので Javascript/Typescriptを使っていきたいので知識のアップデートを行なった
- ブルベーリー本とJest本を読んで Typescriptやテスト・Storybookについての学びを深めるようにした
それぞれざっと一通り読んだだけなので引き続き勉強していきたい
- Reactの新しい公式サイトのチュートリアルに触れた
特にHook周りの理解を深めたかったので読んだ。結構レベルアップできたと思う反面、ここまで重厚なフロントエンドを書きたくはないかもとも思った
- Svelteに触れ始めた
自分にとってのReactの良さと過剰な感じを解消できるかもと思い勉強し始めた。まだ基本の部分しか触れていないのでまだそのメリットを感じ取れてはいない
実は休職したことで自分のソフトウェア開発技術の志向と現職とのギャップを再確認してしまった。 当面は短時間勤務を続けるが、自分の病気ことや生活習慣の改善に合わせて仕事に関しても生まれ変わった方が良いのかもしれない。
まとめ
もう若くないし昔みたいに頑張り過ぎずに健康第一で好きなことをやるべし!
OWASP ZAP でペネトレーションテストを学ぶ(後編)
- これは何の記録か?
- OWASP ZAP を試してみた感想
- 準備
- アプリケーションを探索する (Explore)
- アプリケーションを攻撃する (Attack)
- 報告する (Report)
- GraphQLとOpenAPI に対するテスト例
- Scriptの使い方
- 最後に
これは何の記録か?
ペネトレーションテストを理解するために、実際にOWASP ZAP (Ver.2.11.1)を使って検証したことのまとめ
前編では、OWASP ZAPのドキュメントを読んで理解したことをまとめた。
試したこと
- OWASP ZAPの基本機能を使ったペネトレーションテストの実施手順
- GraphQL と OpenAPI のURLを取得するためのスキーマ定義のインポート
- リクエストとレスポンスのデータを動的変更するためのScriptの作成
試していないこと(いずれ試したい)
- OWASP ZAP を Dockerコンテナから実行する
- CI/CDパイプラインからOWASP ZAPでぺネトレーションテストを実行する
- OWASP ZAP を 活用した手動ペネトレーションテストの実施
OWASP ZAP を試してみた感想
この後の記録が長いので感想を先に書いておく
- ペネトレーションテストが導入しやすい
- このツールに頼り切るだけでは必要な検査はカバー出来ない
- SPA(CSR)のようなサーバーとの通信が発生しないフロントエンドアプリは検査しづらい
- 検証結果・探索結果が適切か判断は人が確認する必要がある
- 検査する脆弱性と検査しない脆弱性を把握しコントロールしなければならない
- 日頃からぺネトレーションテストを意識した準備と対応が大事
準備
インストールは前編に書いているので省略。
テスト対象Webアプリ
OWASPが提供している WebGoat をローカルPCのDockerから起動して利用した。 認証機能を持つため、予めユーザーアカウントを登録しておいた。
クライアント環境のプロキシ設定
ブラウザをOWASP ZAPから起動させる場合、事前に設定することは無かった。
通常、ブラウザとサーバー間の通信(リクエストとレスポンス)を傍受したり書き換えられるようにするには、クライアント端末でOWASP ZAPをプロキシとする設定が必要。 OWASP ZAP がWebdriverを使ってブラウザを制御することでこの設定が無くても通信の探索が出来ていると考えている。
アプリケーションを探索する (Explore)
テスト対象アプリケーションにアクセスする URL とその通信で送受信した リクエスト と レスポンス を探索し収集していく。
手動で探索する(Manual Explore)
ブラウザを手動で操作することで、その時の通信情報をOWASP ZAPにキャプチャさせる。
- Workspaceの『Quick Start』タブから『Manual Explore』を選ぶ
- URL to explore に、探索するアプリのルートURL (e.g. http://localhost:8081/WebGoat)を入力する
- Enable HUD を利用しない場合はチェックを外す *1 *2
- Explore your applicationから、探索に使うブラウザを選択する
- Launch Browseを押すとブラウザが起動される
- 起動したブラウザでアプリを操作すると通信情報がキャプチャされていく
- 一通り操作を終えたらブラウザを閉じるとOWASP ZAPの探索も終了する

通信の取得が目的なので以下のようなリクエスト送信が発生する操作を行う
- リンクをクリックする
- ボタンをクリックする
- フォームに入力する
- フォームをSubmitする
またこの後の自動探索を円滑に進めるための情報や操作も取得する
- 想定通りのレスポンスが返るような操作
- リクエストのqueryとbodyに含めるパラメータの組み合わせパターンを網羅する
- 認証・認可に必要な情報が取得できる操作
- ログイン状態(ログイン中orログアウト中)が把握できる情報の取得
- ユーザーロールごとの探索
URLをContextで管理する
探索した通信情報(送信したリクエストと受信したレスポンス)は、URLと共に記録される。 SiteツリーではURLをパスの階層構造で表示し、Historyタブは探索した時系列で表示する。
探索されたURLには検査対象外の外部サイトが含まれたりするので、脆弱性検査したいURLをContextに追加する。
Contextで特定の関係にURLをまとめて管理することで、SpiderやActive Scanの検査対象を絞ったり(スコープ)、探索不要な外部サイトに誤って攻撃することを防ぐことができる。 また認証方法やセッション管理、ユーザーロールの登録などはContextで設定することになる。
Contextは検査範囲ごとに複数用意し管理することができる。
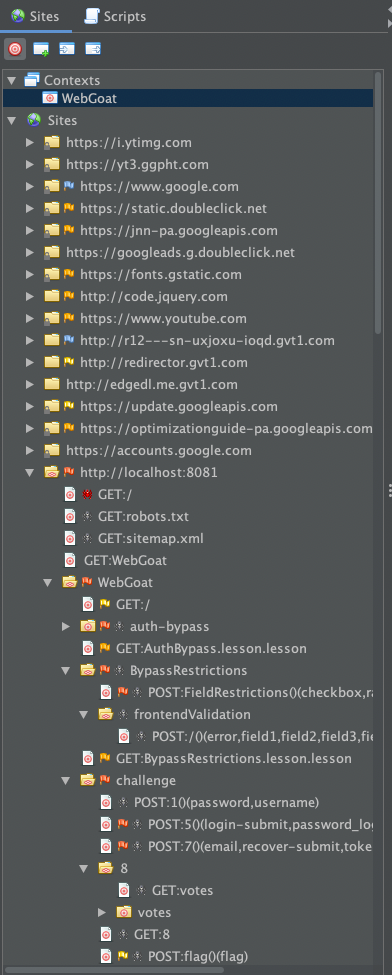
認証方法・セッション管理方法を設定する
アプリケーションの認証情報を設定しておくことで、認証後の画面と機能を探索できるようにする。認証設定はContext をダブルクリックするか Session Properties メニューから行う
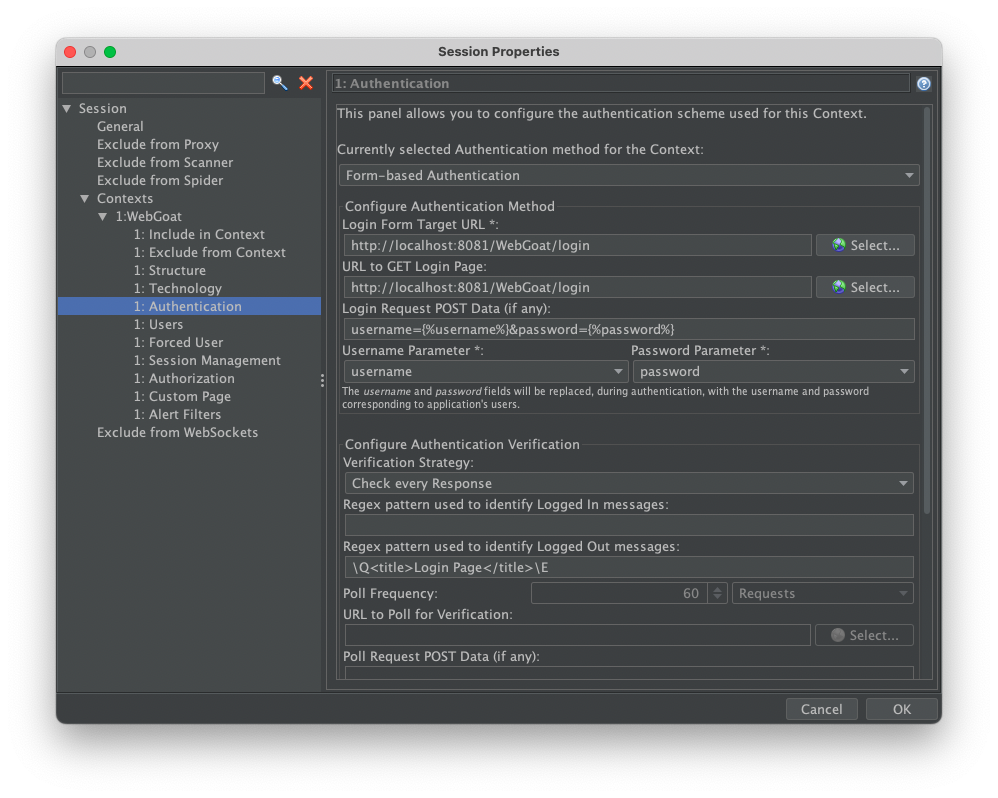
Authentication Method
Form認証やHTTP認証などを指定する。他にも手動で認証操作を行ったり、カスタムスクリプトで認証を実行できたりする。
Form認証を例にすると、ログイン認証を行うリクエストURL と 必要ならページURLを用意し、POSTで渡す認証情報(credential)を定義する。これらの情報は探索済みのリクエストから Flag as Context で取り込むことができる。
UsernameとPasswordに渡す値は、{%username%} と {%password%} と変数で指定することで、Userごとに認証情報の値が設定できる
Authentication Verification
送受信するリクエストとレスポンスの情報から、ログイン中またはログアウト中かを判断するAuthentication Stratagy とパターンを設定する
- Check every Response: レスポンスに含まれる情報で判断する。例えばhtmlの中にログイン中であることが識別できる リンク・アイコン・メッセージの有無などを検索する
- Check every Request: リクエストに含まれる情報で判断する。例えば、ヘッダに認証トークンの含まれているかどうかを検索する
- Check every Request of Response: リクエストとレスポンスの両方で判断する
- Poll the Specified URL: 指定した間隔で認証有無が判断できるURLにリクエストを送信した際のレスポンス情報で現在がログイン中かどうかを判断する。
Users
OWASP ZAP からWebアプリケーションにアクセスするときのUserが作成できる。UserはAuthentication Method で作成した username と password パラメータへの値を登録できるので、ロール別に複数Userを用意して使い分けることで、テストの網羅性を上げることができる。
Forced User
ログイン認証が必要なリクエストで利用するユーザーをUsersから指定する。この機能を利用するには探索やスキャンの前に ツールバーの "Forced User Mode" (鍵アイコン) をEnabledにする必要がある。
これとは別にSpiderやActive Scan実行時にUserが選択できるが、検証ではここでUserを選択しただけだと認証情報を利用してくれなかったので、Forced User Modeは必ず有効にする必要がありそうだった。
セッション管理
Webアプリのセッション管理方法を指定することができる。
- Cookie-Based: CookieにセッションID(トークン)を管理する方法。別途、トークンを管理するCookie名を設定する
- HTTP Authentication: リクエストヘッダで "Authorization" パラメータと値を渡す方法
- Script-Based: 上記以外のセッション管理方式は、スクリプトを作成し管理することができる。
URLを自動探索する
Spider で探索する
SpiderはWebアプリをクローリングしてURLを自動探索する機能。 受信したレスポンスBodyに含まれる情報から、検索したURLにリクエストを送信することを繰り返して、URLと通信情報を取得する
Ajax Spider で探索する
アドオンとしてOWASP ZAPにプリインストールされているもう一つのSpider。
前述のSpider *3は、静的なURLリンクが検出できるがレスポンスから読み取れないURLは検出できない。 Ajax Spiderはブラウザを起動して実際にボタンやリンクを操作することで動的に生成されるリクエストURLを検出することができる。*4
Forced Browse で更にURLを探索する
Webアプリ用のミドルウェアやフレームワークによって生成されるディレクトリなどは、開発チームの意図に関係なく公開されてしまうことがある。このようなディレクトリはWebアプリ内のページ操作では探索できず、直接URLをリクエストすることで探索できる。 このようなディレクトリ名からURLを生成して探索を行う機能がForced Browserアドオンでプリインストールされている。
ディレクトリ名のリストファイルは、プリセットされているもの、アドオンで追加するもの、独自にカスタマイズして追加するものが使える。
自動探索を行う際の注意事項
それぞれの機能の役割に従ってURLを網羅的に探索できるが以下のようなことに注意する
- 検索対象の範囲指定を適切にする
- 必要以上にURLを探索することで、外部サイトへアクセスしてしまう可能性がある
- 検索の深さが大きいため再帰的に何度も探索してしまい探索が終わらない。
これらは実行する前にOptionで設定ができるので、検査仕様を決めた上で実施するとよい
- 検査結果が正しいか確認し、必要であれば修正して再実行する
適切な値で送信しないと適切なレスポンスが受信できない場合もあるので手動で修正する必要がある。
他にも後述する リクエストURLの「パスパラメータ」や「クエリパラメータ」といったURLの構造の調整 (Structural Modifiers)も必要に応じて設定する
データ駆動コンテンツ (Data Driven Content)
標準ではURLが異なれば機能も異なると認識して整理されるが、パスの一部をパラメータとして利用するケースがある。
例: ユーザーの詳細情報を取得するURLに /user/{userId}/detail のような ユーザーIDをパスに含める場合。
この場合はContextのStructure設定で "Data Drive Node" として動作するURLパスを正規表現で定義する。
構造パラメータ (Structural Parameters)
先ほどのData Driven とは逆で、URLは同じだがクエリパラメータの値によって機能が別れるケースもある。
例: ユーザーの詳細情報を取得するURL /user/detail?userId={userId}&userType={userType} があり、ユーザーの種別(userType)によって返される画面が異なる場合。*5
この場合はContextのStructure設定で "Structural Parameter" として動作するクエリパラメータを正規表現で定義することで、クエリパラメータの値によってノードを分けて管理させる。
アプリケーションを攻撃する (Attack)
探索したURLや通信情報を基にWebアプリケーションの脆弱性を検査する。これを "スキャン" と呼ぶ。
スキャン方法は"Passive Scan" と "Active Scan" の2種類があり、特定できる脆弱性が異なる。
スキャンする脆弱性は "スキャンルール" として定義されている。
スキャンルール
スキャンルールは脆弱性を特定するための方法を定義したもので、定義内容に基づいてスキャンを実行する。
スキャンルールは定期的に更新されており、OWASP ZAP にプリセットされている "Release"版だけでなく、検証段階に応じて "Beta" "Alpha" とされているルールもアドオンで追加したり、独自のカスタムルールを作成してスキャンさせることもできる。
どのようなルールが定義されているかは公式マニュアルを参照。次のリンクは "Rlease"版で定義されているスキャンルール。
OWASP ZAP – Passive Scan Rules
スキャンポリシー
スキャンポリシー(Scan Policy)は、スキャンルールに対する実行レベルが定義できる。*6
Threshold
どのレベルで潜在的な脆弱性を検査・報告するかをが設定できる。スキャンルールごとに Low~High および OFF を選択する
- High: そのスキャンルールの最低限の検査だけに限定する。検査時間は早くなるが、潜在的な脆弱性が検索されにくくなる。
- Low: そのスキャンルールで定義されているすべての検査を実施する。潜在的な脆弱性が特定されやすいが、偽陽性は増え検索時間も長くなる
- Medium: High と Low の中間。デフォルト設定は大体これ。 *OFF: そのスキャンルールで定義されている脆弱性は検査しない(スキップする)
Strength
脆弱性を特定するための攻撃数を制御する。これはActive Scanのみの設定。スキャンルールごとに Low~High または Insane を選択する
- High:より多くの攻撃を行うので発見する脆弱性の数も増える。その分、検索時間が長い。
- Low: 攻撃の数が少なくなるので検索時間は短い。その分、脆弱性の特定が漏れるので偽陰性となる可能性がある。
- Medium: High と Low の中間。デフォルト設定は大体これ。
- Insane: 非常に多くの検査を実施するので時間がかかる。アプリ全体ではなく特定の機能に対して行うのがおすすめ。*7
Passive Scan 結果を確認する
Passive Scanは "送信リクエスト" と "受信レスポンス" の内容を基にスキャンする。出力された情報から脆弱性を診断するだけで意図的な攻撃は行わない。
Passive Scanは これまでの探索の中で自動的に行われており、検出された脆弱性はAlertに登録される。同じリクエストで再スキャンしたい場合は、リクエストを再送信したりSpiderを実行する。
Active Scan を実施する
これまで探索したURL(リクエスト情報)に対して、既知の攻撃を行うことで潜在的な脆弱性を検出する。スキャン対象アプリケーションへ実際に攻撃を行うことになるので、外部サイトなどが対象に含まれないように注意が必要。
実行手順
- ツールバーの一番左にあるModeプルダウンを ”Protected Mode” にする。Protecte ModeはSocpe対象のURLだけを攻撃対象とする
- テスト対象アプリが認証機能(Authentication)を持つなら、ツールバーの "Forced User Mode"(鍵アイコン)を有効にする
- テストするContextを右クリックし Active Scan を選択する
- ダイアログが表示されるので、利用するUserやScanPolicy、Technologyの設定を確認する。
- スキャンを開始する。
対象外アプリケーションを攻撃しないように設定する
テスト対象外のアプリへの攻撃を防ぐために必ず次の設定を行う。
- "Protect Mode" にすることでScope内のURLに対してだけ攻撃を行う。
- "Scope"は、Contextに含めることで対象となる。
つまり探索したURLのうち、テストするURLだけをContextに指定するようにし、Protect Modeで実行すること。
スキャンルール "Cross Site Scripting (DOM Based) "
Active Scanのルールの中に標準インストールされているアドオン "Cross Site Scripting (DOM Based)" は、DOM Based XSS を検出するルールであり、サーバーとの通信を行わず、クライアントサイド(フロントエンドアプリ)だけで発生する脆弱性を検出することができる。
そのため、ブラウザを起動してテストを行うので実行にとても時間を有する*8 。
このためこのスキャンルールを利用する際は、適切な設定や単独で実行するなどの対応が必要そうだと感じた。
Manual Scan を 実施する
最後に Active Scan では検出できない脆弱性を手動操作で検出する。
セキュリティテスト以外のテストでも同じことが言えるが、全てのテストを自動化することは難しい。
特にセキュリティテストは手法が決まっているわけでは無く攻撃者がどんな方法で攻撃を仕掛けるかはわからないし、開発プロセスや技術スタックによってアプリケーション特有のセキュリティホールが存在したりするので、自動化による汎用的なテストだけでは不十分なことが多い。
OWASP ZAPのマニュアルでも「ここまでの操作で基本的な脆弱性は発見できるが、より多くの脆弱性を発見するにはアプリケーションの手動テストも必要になる。」と説明するのと同時に、OWASP Testing Guideが紹介されている。
今回はツールを利用することが目的の一つだったので、手動テストは省略しているが、公式マニュアルでも手動テストを支援する方法を今後紹介する予定としている。
報告する (Report)
アラートの確認
画面下部の Alertタブで検出された脆弱性の詳細が確認できる。
Alert はリスクによって "High" > "Medium" > "Low" > "Informational" > "False Positive" の5段階のレベルがあり、脆弱性ごとにデフォルト値があるがカスタマイズもできる。
レポートを出力する
メニューバーの[Report] > [Generate Rerport] からレポートの出力が行える。 複数のレポートテンプレートが用意されているので、必要なものを選択して出力を行う。
GraphQLとOpenAPI に対するテスト例
公開されているAPIに対するテストを行う場合、API側が公開しているスキーマ定義を取り込んでURLを探索することができる。
OpenAPI (REST API) の API定義を取り込む
メニューバー の [Import] > [Import a OpenAPI definition from...] から 2種類のどちらかの方法で取り込む。
- ローカルファイルから探索する: OpenAPI仕様に準拠した定義ファイル(.json/.yaml)をインポートする
- URLから探索する: 公開されているOpenAPIドキュメント(Swagger UIなど)のURLを指定して取り込む
上記とは別にテスト対象アプリケーションのエンドポイントURLを指定し探索を行う。 探索したAPIはこれまで通り、URLが登録され自動的にPassive Scanまで行われるので、あとはこれまで記載した通り適切な送受信が行えるように手動で設定を行う。
GraphQL の API定義を取り込む
メニューバー の [Import] > [Import a GraphQL schema from...] から 2種類のどちらかの方法で取り込む。
- ローカルファイルから探索する: GraphQLのスキーマ定義ファイル(*.graphql)を指定して取り込む
- GraphQLエンドポイントURLから探索する: WebアプリケーションのGraphQL API用のエンドポイントURL (例: http://localhost:4000/graphql) を指定する。
上記とは別にテスト対象アプリケーションのエンドポイントURLを指定し探索を行う。
探索した後は、OpenAPIと同様に手動で補完を行う。
Scriptの使い方
通信の際に、受信したレスポンスに含まれる動的なパラメータを次のリクエストに渡して取得したい場合など、OWASP ZAP の標準機能やアドオンでは実現できない処理をスクリプトを用意して実行させることができる。
今回REST APIの検証で以下のアプリを利用したが、このアプリはCSRF対策として、Spring Secruityの利用した二重送信Cookie(Double-Submit-Cookie)を採用しており、サーバーはログイン認証が成功するとcsrfトークンを生成してクライアントのCookieにセットする。 クライアントではセットされたCookieからトークンの値を取得しリクエストヘッダーで渡して送信するようにしている。
このプロセスはOWASP ZAP では対応していないので、Scripts の "HTTPSender"を利用して、レスポンスを受信した時とリクエストを送信する時に動的なcsrfトークンをセットするようにしている。
var regexUrl = /\/login$/i;
var antiCsrfTokenName = "XSRF-TOKEN";
var reqHeaderCsrfTokenName = "X-XSRF-TOKEN";
// Response受信時の処理
function responseReceived(msg, initiator, helper) {
// print('responseReceived called for url=' + msg.getRequestHeader().getURI().toString());
// ログイン認証のレスポンスの場合に処理を行う *リクエストURIの最後が "/login"が該当する
if (msg.getRequestHeader().getURI().toString().match(regexUrl) != null) {
// レスポンスヘッダに含まれる Set-Cookieを検索する
var cookies = msg.getResponseHeader().getCookieParams();
var iterator = cookies.iterator();
while(iterator.hasNext()){
var cookie = iterator.next();
// セットするCookieが、CSRF対策トークンで、値が渡される場合
if(cookie.getName().equals(antiCsrfTokenName) && cookie.getValue() != ""){
// print('Latest CSRF Token value: ' + cookie.getValue());
// Global変数にcsrf対策トークンの値をセットする
org.zaproxy.zap.extension.script.ScriptVars.setGlobalVar("anti.csrf.token.value", cookie.getValue());
}
}
}
}
// リクエスト送信時
function sendingRequest(msg, initiator, helper) {
// 送信メソッドが"GET"以外、かつ ログイン認証ではない場合
if(msg.getRequestHeader().getMethod() != "GET" && msg.getRequestHeader().getURI().toString().match(regexUrl) == null){
// Global変数から csrfトークンを取得する
var antiCsrfTokenValue = org.zaproxy.zap.extension.script.ScriptVars.getGlobalVar("anti.csrf.token.value");
// print("antiCsrfTokenValue:" + antiCsrfTokenValue);
// HttpRequestHeadeにcsrfトークンを追加する
msg.getRequestHeader().setHeader(reqHeaderCsrfTokenName, antiCsrfTokenValue);
// Cokieを取得する
var cookies = msg.getCookieParams();
var iterator = cookies.iterator();
while(iterator.hasNext()){
var cookie = iterator.next();
// cookieがcsrf対策トークンの場合
if(cookie.getName().equals(antiCsrfTokenName)){
var secureTokenValue = cookie.getValue();
// print("secureTokenValue:" + secureTokenValue);
// csrfトークンの値がGlobal変数とCookieで異なればCookieの値をグローバル変数に更新する
if (antiCsrfTokenValue != null && !secureTokenValue.equals(antiCsrfTokenValue)) {
cookie.setValue(antiCsrfTokenValue);
}
return;
}
}
}else{
// HTTPリクエストヘッダーをクリアする
msg.getRequestHeader().setHeader(reqHeaderCsrfTokenName, null);
}
}
このスクリプトを有効にすると、探索やスキャンが行われるたびに実行されるようになる。
最後に
かなり長くなったが、実際に試行錯誤しながら使ってみることで、OWASP ZAP の仕組みがわかったし、ペネトレーションテストの勘所も掴めた気がする。
後は脆弱性への理解を深めて「どんな検証をするべきか」「どこまで検証するべきか」などの知識を深掘りして使いこなせるようになりたい。
*1:HUD(Heads Up Display)はOWASP ZAPをブラウザに重ねて表示できる機能。ブラウザとOWASP ZAPを往復しなくてもスキャン結果の確認や簡単な設定が行えるので便利。
*2:OFFにしたのはデュアルディスプレイだったのと、たまに機能しなくなることがあったため。
*3:マニュアルなどでは(Traditional) Spiderと書かれている
*4:SPAのようなクライアントサイドで画面を更新する操作はサーバーとの通信が発生しないため検出できない。
*5:実際はuserTypeなんて指定しないで、userIdを基にサーバー側でuserTypeを特定するとは思う
*6:Scan Policyの設定はActive Scanに対して行うが、ThresholdはPassive Scanでも有効なので便宜的ではあるがここでまとめて記載した
*7:Insaneという用語を使っているがそれ自体に差別的な意味は無い旨の説明が公式マニュアルに記載されている。
*8:検証でも数ページの探索を1日以上かけても進捗が50%にならずに途中でやめた。
OWASP ZAP でペネトレーションテストを学ぶ(前編)
これは何?
前職では、アプリケーションセキュリティテスト(AST)ツールの販売に関わっていて、SASTやSCAは詳しくなったが、DASTに関してはツールはもちろんテスト自体の知見もあまり身につけられていなかった。
そんな中、現職の年間目標の一つにDASTを取り入れることを挙げていたのと、開発中のWebアプリケーションの脆弱性診断を委託することになり、ペネトレーションテストを学びたいモチベーションが出てきたので、夏休みの宿題としてOWASP ZAPの使いながらベネトレーションテストの基本を学ぶことにした。
前編では座学としてZAPを使う前にペネトレーションテストについてOWASP ZAPの公式マニュアルを中心に学んだことを整理する。
後編では実際にZAPを使ったペネトレーションテストを実行して理解したことをまとめる。
なお、本来の目標は「ZAPによるペネトレーションテストをCI/CDパイプラインに組み込んで自動プロセス化する」だったが、予定通り進まなかったので、宿題事項は引き続き検証を進める予定。
ペネトレーションテストとは
悪意ある攻撃者のように振る舞ってシステムに侵入し、データを盗んだりサービスが正常に動作出来なくなるような攻撃を目的として実施するテストのこと
目的
脆弱性を探し出しその脆弱性に対処できるようにすること。また、特定の攻撃に対してシステムが脆弱でないことを検証したり、検出した脆弱性を修正して再検証すること。
メリット
動作しているシステムに対して実際にテストして脆弱性を検出するため、誤検知(存在しない脆弱性が報告されるなど)が少なく正確な結果が得られる。 他にも、防御の仕組みの検証、対応策の検証、セキュリティポリシーの遵守の確認などにも利用される。
その反面、検証用環境を構築し必要なデータを投入するなどの準備を行なったり、実際にシステムとの通信を行って検証するので、テストの実施に時間が掛かる。
ペネトレーションテストの基本手順
- 探索する(Explore): テスト対象のシステムを調べる
- システムが持つ全ての機能やエンドポイントを特定する
- パッチはインストールされているかなどシステムの情報を調べる
- システムに隠されているコンテンツや既知の脆弱性、弱点の兆候などを探索する
- 攻撃する(Attack): 探索した情報を元に脆弱性を検査する
- 報告する(Report): 検査結果を報告する
ペネトレーションテストで意識すること
- アプリケーションが提供する全ての機能を検査する
- 機能を利用するための全てのURLやエンドポイントをリストアップする
- 全ての機能にアクセスするための最低限のユーザー情報やデータを予め登録する
- 認証や外部のWAFに守られている機能も検査する
- 悪意あるユーザーが認証を突破したら?
- 一般ユーザーを装ってサービスが利用していたら?
- 公開していなくても機能やエンドポイントが存在するなら攻撃対象になり得る
- 未知の脆弱性の検出は難しい
- ペネトレーションテストは既知の脆弱性に対する攻撃をシミュレートする
- ペネトレーションテスト以外のセキュリティテストも併用することで脆弱性を減らす
- 自動テストと手動テストを使い分ける
- 自動テストは基本的な脆弱性検査を回帰的に検査し
- 手動テストは操作が複雑など自動では対応できないテストに集中する
- クライアントサイドで処理が完結するSPAだとZAPのようなサーバーとの通信内容を検証するツールでは検知できない。
OWASP ZAP とは
OWASP について
Open Web Application Security Project(OWASP) は、ソフトウェアのセキュリティ改善を目的とした非営利な団体
OWASPでは、ソフトウェアのセキュリティに関する様々なプロジェクトが存在する。中でも OWASP Top Ten はリスクの高い脆弱性や攻撃されることが多い脆弱性などを統計・分析した結果を公開したものでソフトウェア開発において手始めに対処するべき脆弱性を理解することに役立っている。
OWASP ZAP の主な特徴や機能
OWASP ZAP (Zed Attack Proxy) は OWASPのフラッグシップ・プロジェクトの一つで、オープンソースで公開されており、無料で利用することができるWebアプリケーション向けの脆弱性スキャナである。
- 中間プロキシとして動作する
- Spider
- Passive Scan (受動的スキャン)
- Active Scan (能動的スキャン)
- ユーザー管理と認証管理およびセッション管理
- テスト実行に必要な認証情報やセッション情報の方式を設定したり管理が行える
- テストを実行するユーザーも選択できる。ユーザーは複数管理が行え、ユーザーごとに認証情報が設定できる。
- アプリケーションにユーザーロールがある場合など、全ロールのユーザーを作成することで全ての機能とエンドポイントがカバーできる。
- アドオン
OWASP ZAP で検出できる脆弱性
- 既知の脆弱性は 脆弱性ごとにScan Rule として定義され公開されている。
- ZAPのデフォルトで検査できるScan Rule はステータスが Releaseとなっているもの。
- その他のステータスには、Alpha, Beta があり、別途アドオンで追加すれば検査が可能になる。
- 独自ルールをScriptで作成して脆弱性を検査することもできる
OWASP ZAPをインストールし、ペネトレーションテストを行う
インストール
- インストーラは下記からダウンロードできる
- Windows版とLinux版は別途、Java 8(JRE 8) 以上をインストールする必要がある
- Mac版はJava 11がバンドルされている
- Docker版もある。基本はCLI設定になるが、ブラウザから操作できるGUIも提供されている模様。(動作未確認です。)
今回の検証では、MacのHomebrew caskを使ってインストールした Version 2.1.1 を利用した
検証に利用するWebアプリ
今回は同じくOWASPのフラッグシップ・プロジェクトである Juice Shop をローカルのDockerで起動し利用した。
Juice Shopはアプリに含まれている脆弱性を攻撃することでソフトウェアのセキュリティを学ぶことができる体験型のWebアプリケーションである。
Juice Shop以外にも同様のWebアプリケーションは VWADとして公開されており、プログラミング言語やフレームワーク、実行環境に対応している。
基本の操作手順
前述のペネトレーションテストの基本手順をZAPで行う。 これは下記のマニュアルを参考にしており、実際に実施したことは 後編にまとめる。
Explorer - 探索する
- Webアプリが提供する全ての機能とエンドポイントURLを探索する。
- ブラウザで実際に全てのリンクやボタンを押したり、全てのフォームを埋めてsubmitすることで、アプリケーションとの通信(リクエストとレスポンス)をキャプチャする
Contextへの登録
- 探索したSite(URL)からテスト対象とするエンドポイントをContextに追加する。
- Contextに追加したサイトは、テストスコープの対象となり、認証情報を指定したユーザーでテストが実施できたり、セッション管理が行えるようになる。
Spider でさらに探索する
- Spiderを利用することで手動では探索できなかったり隠れていたURLを探索する
- 先に手動で探索したサイトをContextに設定しておくことで、ContextベースでSpiderを実行することができるので、認証情報を使ったり、探索が必要なサイトだけを対象にすることができる。
- 手動探索とTraditional Spiderの探索結果は重複するURLも多いので先に認証処理に関するエンドポイントを中心に手動探索してContext管理を行い、Traditional Spiderを使うと効率的かもしれない。
- Ajax Spiderも実行することで動的に生成されるリンクも探索する。
- Ajax Spiderの実行にはブラウザが必要になる。
Forced Browse - 強制ブラウズ
- 参照されていないファイルやディレクトリを発見するための探索機能。 “Forced Browse“アドオンのインストールが必要
- 一般的にURLディレクトリ(パス)の名称として使われるキーワードリストを用意して、URLを生成して探索を行うことで、元に該当するURLが無いか探索する。
- 存在するディレクトリ名を発見したら更に再帰的にパスを生成して探索する。このため探索に時間もシステムへの負荷も掛かる。
- デフォルトでは、'directory-list-1.0.txt' ファイルがインストールされている。
- 他のディレクトリリストもマーケットプレイスに公開されていたり、独自に用意してインポートすることもできる。
Passive Scan の実施
- ここまでの手動探索やSpider探索などで、探索と同時にScanを実施していた。
- つまり、Passive Scanは明示的に独立して実行する必要がない。
Active Scan の実施
- 探索したサイトに対して基本的な脆弱性を特定する検査を実施する。
- 実際のシステムに攻撃を仕掛けるので、スコープ対象以外のサイトURLへ攻撃しないように、スコープ指定を行い、Protectモードで実行することがお勧め。
- エンドポイントの数が少なくても全てを完了するまでに5−6時間掛かった。実際のアプリへのテストなら並列実行などを検討した方が良さそう。
レポートを作成する
- 検査結果をファイルに出力することができる。
- ファイル出力しなくても、ZAPのセッションを保存すれば ZAPからも確認できる。
手動テスト
Active Scanによる自動テストでは発見できない脆弱性を検証するために、手動テストを実行する。
詳細は WSTG (Web Security Testing Guide)を参照
公式ドキュメントでは、将来的にZAPが手動テストをどのように支援できるかを紹介する予定があるそうだが現時点では非公開。
例えば、探索したリクエスト/レスポンスにBreakpointを打ち、通信内容を書き換えてテストする操作なども手動テストの一種だと考える。
今回はZAPを使ってペネトレーションテストを自動実行することが目的でもあるため省略する。
前編はここまで。
実際にZAP DesktopUI から Juice Shopへのペネトレーションテストを実施した結果は、後編にまとめる。
追記:
Active Scanで、Cross Site Scripting (DOM Based) の検査が行われるようになっていて、SPAこれならクライアントサイドで発生するXSSの検証ができるのかもしれない。
ただこのルールはまだ Beta版で、下記の説明の通り ヘッドレスモードのブラウザで検証しているせいか、他のルールと比較して圧倒的に時間を消費している*1ので、現時点で有効なルールではない気がする。
フロントエンドアプリ(React)で使うライブラリを最新にしたらテストでエラーになったので色々直した話
モチベーション
自分のフロンエンド技術を維持するため、サンプルアプリを作って試していたり、依存関係のバージョンも最新で動かすようにしている。 だけど最近テスト実行時にこれまで遭遇しなかったエラーが出るようになって対応が難しかった。 一応、テストは全て通るようにはなったけど、結構大掛かりな対応になりそうなので、まとめておく。
多分、内容は更新していくかm
エラーになったpackage.json
サンプルアプリケーションとエラーとなった時点のpackage.json を基点として記載しておく
{
"name": "project-frontend-dev-process",
"version": "0.1.0",
"private": true,
"license": "MIT",
"engines": {
"node": "16.x"
},
"packageManager": "yarn@1.22.19",
"dependencies": {
"@emotion/react": "^11.9.3",
"@emotion/styled": "^11.9.3",
"@fontsource/roboto": "^4.5.7",
"@mui/icons-material": "^5.8.4",
"@mui/material": "^5.9.1",
"@tanstack/react-query": "^4.0.10",
"@tanstack/react-query-devtools": "^4.0.10",
"axios": "^0.27.2",
"react": "^18.2.0",
"react-dom": "^18.2.0",
"recoil": "^0.7.4",
"ulid": "^2.3.0",
"web-vitals": "^2.1.4"
},
"devDependencies": {
"@storybook/addon-a11y": "^6.5.9",
"@storybook/addon-actions": "^6.5.9",
"@storybook/addon-essentials": "^6.5.9",
"@storybook/addon-interactions": "^6.5.9",
"@storybook/addon-links": "^6.5.9",
"@storybook/addon-storyshots": "^6.5.9",
"@storybook/builder-webpack5": "^6.5.9",
"@storybook/jest": "^0.0.10",
"@storybook/manager-webpack5": "^6.5.9",
"@storybook/node-logger": "^6.5.9",
"@storybook/preset-create-react-app": "^4.1.2",
"@storybook/react": "^6.5.9",
"@storybook/testing-library": "^0.0.13",
"@storybook/testing-react": "^1.3.0",
"@testing-library/jest-dom": "^5.16.4",
"@testing-library/react": "^13.3.0",
"@testing-library/react-hooks": "^8.0.1",
"@testing-library/user-event": "^14.2.6",
"@types/jest": "^28.1.6",
"@types/node": "^18.0.6",
"@types/react": "^18.0.15",
"@types/react-dom": "^18.0.6",
"chromatic": "^6.7.1",
"jest": "^28.1.3",
"jest-environment-jsdom": "^28.1.3",
"msw": "^0.44.2",
"msw-storybook-addon": "^1.6.3",
"prettier": "^2.6.2",
"react-scripts": "^5.0.1",
"ts-jest": "^28.0.7",
"typescript": "^4.7.4",
"webpack": "^5.73.0"
},
"resolutions": {
"react-test-renderer": "^18.2.0"
},
"scripts": {
"start": "react-scripts start",
"build": "react-scripts build",
"test": "react-scripts test",
"eject": "react-scripts eject",
"eslint": "eslint . --ext .js,.jsx,.ts,.tsx",
"storybook": "start-storybook -p 6006",
"build-storybook": "build-storybook"
},
"eslintConfig": {
"extends": [
"react-app",
"react-app/jest"
],
"overrides": [
{
"files": [
"**/*.stories.*"
],
"rules": {
"import/no-anonymous-default-export": "off"
}
}
]
},
"browserslist": {
"production": [
">0.2%",
"not dead",
"not op_mini all"
],
"development": [
"last 1 chrome version",
"last 1 firefox version",
"last 1 safari version"
]
},
"jest": {
"testMatch": [
"**/__tests__/**/*.test.[tj]s?(x)"
],
"transform": {
"^.+\\.(ts|tsx)$": "ts-jest"
}
},
"msw": {
"workerDirectory": "public"
},
"homepage": "."
}
起きたこと
Serverアクセスする所でNetworkエラーが発生した
MSWを0.42.1 までだと発生しない。 だけど設定してあるhandlerに対しても、handleしていないと出てはいた
ServerのリクエストURLにホストをつけた
https://example.com を付けるようにした mswのHandlerもこのホストで受け付けるようにした
結果、http://localhost CrossOrigin エラーが発生した
Jestの設定に testEnvironmentを指定しようとした
react-scriptではこの変数に対応していないことを知る
ここでreact-scriptsのJestがV27なことに気づく
v28を使いたいのとこの辺がのversion違いがエラーの原因な気がしたので、scriptsのtestコマンドを react-scripts を介さずに "test": "jest" に変えた
そうしたら他のテストでもエラーが発生し始め、全体的にテストが通らなくなってきたので、見直すことにした
jest.config.ts と jest.setup.ts を作る
jest.setup.ts は CreateReactAppが作成していた、src/setupTests.js を 名前を変えただけ。 rootに持ってきたのは jest.config.tsと並べて管理したかったから
ちなみにjest.setup.jsだとimport moduleのエラーが出てしまい、 import "@testing-library/jest-dom" が利かず、jest-dom のライブラリを利用している テストファイルごとに付けなければいけなくなった。
これを.tsに変えると直るのだが、モジュールシステムがわからない。
jest.configの方も以下を参考に .ts に変えた。 この過程で ts-node をインストールしている
IntelliJでテストを単独実行すると 前述の jest.setup.js をみてくれない
CLIではなく、IDE上で特定のケースのテストを実行しようとする以下のようなエラーが出る
expect(...).toBeInTheDocument is not a function TypeError: expect(...).toBeInTheDocument is not a function
toBeInTheDocument() は、jest-domに含まれているので、setupTests.ts が参照されていないのではと考えてConfigurationを見たら Jest packageが、react-scripts を参照していたので、これを jest に変えたら通った。
Documentの内容から、react-scripts を使って実行するのが最優先になっているのだと思った。 なので react-scripts をremove を考え始めている
Mockの状態をクリアする必要が出てきた
Mockを使って toHaveBeenCalled() で検証していた箇所が軒並みFailedになり始めた。 テストを繰り返し行う場合や実行順で影響が出るので、テストごとに状態がクリアされていないと判断し、クリア処理を追加した
beforeEach(() => mockedMutate.mockClear());
今までこれが無くてもテストが通っていたのは、 react-scripts が何かをおこなっていたからだと予測できるが、深く追ってはいない。
Storyshots.test が失敗する
Storybookのアドオンを利用したSnapshotテストがエラーを返していた。
FAIL src/__tests__/Storyshots.test.ts
● Test suite failed to run
Jest encountered an unexpected token
Jest failed to parse a file. This happens e.g. when your code or its dependencies use non-standard JavaScript syntax, or when Jest is not configured to support such syntax.
Out of the box Jest supports Babel, which will be used to transform your files into valid JS based on your Babel configuration.
By default "node_modules" folder is ignored by transformers.
Here's what you can do:
• If you are trying to use ECMAScript Modules, see https://jestjs.io/docs/ecmascript-modules for how to enable it.
• If you are trying to use TypeScript, see https://jestjs.io/docs/getting-started#using-typescript
• To have some of your "node_modules" files transformed, you can specify a custom "transformIgnorePatterns" in your config.
• If you need a custom transformation specify a "transform" option in your config.
• If you simply want to mock your non-JS modules (e.g. binary assets) you can stub them out with the "moduleNameMapper" config option.
You'll find more details and examples of these config options in the docs:
https://jestjs.io/docs/configuration
For information about custom transformations, see:
https://jestjs.io/docs/code-transformation
Details:
/Users/kazokmr/IdeaProjects/project-frontend-dev-process/.storybook/preview.js:3
import "../src/index.css";
^^^^^^
SyntaxError: Cannot use import statement outside a module
jest.setup.js の import "@testing-library/jest-dom" で出力されたエラーと同じだったので、 ./.storybook/preview.js を .ts に変えたらエラーが変わった
Details:
/Users/kazokmr/IdeaProjects/project-frontend-dev-process/src/index.css:1
({"Object.<anonymous>":function(module,exports,require,__dirname,__filename,jest){body {
^
SyntaxError: Unexpected token '{'
こちらの記事を参考に ./.jest/style.ts 作って以下のように1行追記し、 jest.config.ts の moduleNameMapperプロパティで cssファイルをこのファイルにマッピングするようにした
export default {};
...
moduleNameMapper: {
"\\.(css|less)$": "<rootDir>/.jest/style.ts"
}
...
一応これでエラーはなくなり、Snapshotも取得できるように戻った。
ただし、以下のようなエラーメッセージは出ているので、react-scriptsを介さない場合の設定に見直す必要はあると思う。 .mdxファイルに対しても同じ対処が必要だった。
● Console
console.error
Unexpected error while loading ./stories/Introduction.stories.mdx: /Users/kazokmr/IdeaProjects/project-frontend-dev-process/src/stories/Introduction.stories.mdx: Support for the experimental syntax 'jsx' isn't currently enabled (11:1):
9 | import StackAlt from './assets/stackalt.svg';
10 |
> 11 | <Meta title="Example/Introduction" />
| ^
12 |
13 | <style>{`
14 | .subheading {
Add @babel/preset-react (https://github.com/babel/babel/tree/main/packages/babel-preset-react) to the 'presets' section of your Babel config to enable transformation.
If you want to leave it as-is, add @babel/plugin-syntax-jsx (https://github.com/babel/babel/tree/main/packages/babel-plugin-syntax-jsx) to the 'plugins' section to enable parsing.
Jest encountered an unexpected token
Jest failed to parse a file. This happens e.g. when your code or its dependencies use non-standard JavaScript syntax, or when Jest is not configured to support such syntax.
Out of the box Jest supports Babel, which will be used to transform your files into valid JS based on your Babel configuration.
By default "node_modules" folder is ignored by transformers.
Here's what you can do:
• If you are trying to use ECMAScript Modules, see https://jestjs.io/docs/ecmascript-modules for how to enable it.
• If you are trying to use TypeScript, see https://jestjs.io/docs/getting-started#using-typescript
• To have some of your "node_modules" files transformed, you can specify a custom "transformIgnorePatterns" in your config.
• If you need a custom transformation specify a "transform" option in your config.
• If you simply want to mock your non-JS modules (e.g. binary assets) you can stub them out with the "moduleNameMapper" config option.
You'll find more details and examples of these config options in the docs:
https://jestjs.io/docs/configuration
For information about custom transformations, see:
https://jestjs.io/docs/code-transformation
Details:
SyntaxError: /Users/kazokmr/IdeaProjects/project-frontend-dev-process/src/stories/Introduction.stories.mdx: Support for the experimental syntax 'jsx' isn't currently enabled (11:1):
9 | import StackAlt from './assets/stackalt.svg';
10 |
> 11 | <Meta title="Example/Introduction" />
| ^
12 |
13 | <style>{`
14 | .subheading {
Add @babel/preset-react (https://github.com/babel/babel/tree/main/packages/babel-preset-react) to the 'presets' section of your Babel config to enable transformation.
If you want to leave it as-is, add @babel/plugin-syntax-jsx (https://github.com/babel/babel/tree/main/packages/babel-plugin-syntax-jsx) to the 'plugins' section to enable parsing.
at instantiate (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/parse-error/credentials.js:61:22)
at instantiate (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/parse-error.js:58:12)
at Parser.toParseError [as raise] (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/tokenizer/index.js:1736:19)
at Parser.raise [as expectOnePlugin] (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/tokenizer/index.js:1800:18)
at Parser.expectOnePlugin [as parseExprAtom] (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/parser/expression.js:1239:16)
at Parser.parseExprAtom [as parseExprSubscripts] (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/parser/expression.js:684:23)
at Parser.parseExprSubscripts [as parseUpdate] (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/parser/expression.js:663:21)
at Parser.parseUpdate [as parseMaybeUnary] (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/parser/expression.js:632:23)
at Parser.parseMaybeUnary [as parseMaybeUnaryOrPrivate] (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/parser/expression.js:384:14)
at Parser.parseMaybeUnaryOrPrivate [as parseExprOps] (/Users/kazokmr/IdeaProjects/project-frontend-dev-process/node_modules/@babel/parser/src/parser/expression.js:394:23)
at Object.error (node_modules/@storybook/client-logger/dist/cjs/index.js:74:67)
at node_modules/@storybook/core-client/dist/cjs/preview/executeLoadable.js:84:32
at Array.forEach (<anonymous>)
at node_modules/@storybook/core-client/dist/cjs/preview/executeLoadable.js:77:18
at Array.forEach (<anonymous>)
at executeLoadable (node_modules/@storybook/core-client/dist/cjs/preview/executeLoadable.js:76:10)
at executeLoadableForChanges (node_modules/@storybook/core-client/dist/cjs/preview/executeLoadable.js:127:20)
at Object.getProjectAnnotations [as nextFn] (node_modules/@storybook/core-client/dist/cjs/preview/start.js:161:84)
モジュールシステム も react-scripts も tsc も何にもわかっていないなぁ自分。
(7.26 追記) 上記の問題は Storyshotsでスナップショットテストを実行する際に、.cssや .mdx ファイルの解析に失敗していることが問題だった。 なので対応としては大きく2つの方法があり、今回はテスト自体への支障が無いと判断して、2の対応をしたことになる
- Jest実行時に解析できるようにファイルの中身を変換する (jest.config の transformオプションを使う)
- Jest実行時にファイルの参照先をモックファイルに変換して無視させる (jest.config の moduleNameMapperオプションを使う)
1は変換するためのモジュールを予めインストールしておき、そのモジュールを指定すると良さそう。
例えば、CSS なら jest-css-modules-transform, MDXなら @storybook/addon-docs/jest-transform-mdx などを使うのが良さそう。と思ったけど、CSSの方はそれでも行けたけど、MDXは追加したモジュールでエラーが出た。
このあと調べること
テストは通っているので、これでコミットはするが大きく2つやるべきことが残っている
snapshotsテストの設定見直し
実行ログではエラーが出ていたり、一部 react-scriptsに依存した設定になっているように見受けられるので調査・対応する。
多分だけど、Storybook全体で設定内容を見直した方が良さそう
(7.26 追記) 前述の通りMDXファイルの解析エラーが問題だったので、今回はCSSの時と同様にモック化したMDXファイルに置き換える対応で解決した。
Viteに移行する
jestなど react-scripts でバンドルしているものは、最新バージョンに追従するのが難しいので、react-scripts (CreateReactApp)からの脱却を考えている。できればライブラリへの依存度が少ない薄いビルドツールを使いたい。
となると vite が候補に挙げられるのでこれを試してみたい
JJUG CCC 2021 Spring 参加レポート
前回の参加が、2019 Spring だったので2年振りです。
簡単に聴いたセッションの感想を書きます。
フロントエンド・バックエンドの分離の道のり
既存システムで JSP + カスタムタグ + JavaScript で開発していたフロントエンドを React に変更して、フロントエンドとバックエンドの開発を明確に分離するまでのお話。
JSPで書いていたものを全てReactで書くのは難しく「画面の共通フレームの部分はJSPのまま、コンテンツ部分をReactで書く。」「初回のリクエストはJSPで返し、以後はReactで非同期で対応する。」などの過渡期の部分の話が聞けたのが面白かった。
フロントエンドの方が採用技術が大きく変わったのでこちらよりの話が多い感じがしたので、バックエンド側で行った話ももう少し聞いてみたかった。
今どき?の Java における例外処理についての考察
Javaの例外の基本から始まり、従来の例外処理とコーディングでの課題を挙げ、他の言語だとどのような書き方ができるかを紹介して、最後は Java16 そして Java17 になるとどのように例外処理が書けるかというお話。
最近Kotlinを勉強したというのもあったので関数型プログラミングでの書き方についても大体理解しながら聴くことができた。
次のLTSになる Java17 だと Switch式, record, sealed class などを駆使すると、どのように例外処理が書けるかを見たら、早く使ってみたいって気持ちになった。
OpenID Connect 1.0 with Spring Security
ちょっと前に自社で、SAML, OAuth2.0, OIDC を調べていて、Spring Securityのリファレンスページ や Auth屋さんの本を読んでいたので、答え合わせをするようなつもりで聴いてみました。
アクセストークンを「切符」で例えて説明されたり、重要な言葉を説明する時に強弱をつけて説明されるので多田さんの話はいつも聴きやすいですね。(この辺は自分も参考にしたいです。)
(OAuth認証の問題の部分については、私自身も他人に説明できるほど理解できていないですが、
本来は認証が成功することでアクセスが許可されるログインユーザーの認証情報に、OAuthの認可の仕組みでアクセスできるようにすることで認証と同等の結果が得られるのが、OAuth認証かなと思っています。
この使い方には明確な規約が無いので、正しく取り扱わないとなりすましログインなどの脆弱性を引き起こすので、OAuthに認証情報を取り扱うときのルールを定めたのがOIDCなのかなと雑に理解しています。)
またSpring Securityだと、OAuth 2.0 Login の機能に OIDCも実装されているので、リファレンスを読んでもOIDC自体のことが分かりにくいんですよね。逆にいえばSpring Security だとOAuth認証とOIDCの違いを意識しなくても使いやすくなっているということかもしれませんが。
サーバーレスAPIをKotlinで開発してみよう
サーバーレスアプリケーションを構築する機会は無いのですが、Kotlinを勉強したばかりというのもあり聴いてみました。
SAMはAWSのサーバーレスアプリケーション開発をサポートするツールなのでAWSでサーバレスアプリをデプロイするまでを簡単に行える感じなのが面白そうでした。
また普段はそこまで気をつけていない、リソース量や初期化時間を考えて設計が大事なこと、テストもLambdaに依存する所と依存しない部分に分けて行うなどの説明がわかりやすく、機会があれば触ってみたいなと感じるセッション内容でした。
JFR などのツールを用いて FullGC や OOME の原因を特定する流れ
JFR や JMC、Memory Analyzerを使った問題解析・原因分析を行う手順を紹介するセッション
前職だと、JConsole、Memory Analyzer は使ったことあったのだけれど、JFR、JMCはやっぱりいいなと思いました。 今の仕事でもここまで原因調査を行う機会が無いのだけれども、いつか必要になるときに触れておきたいですね。
あとJFRは、本番稼働中は常時有効にしておくものなのかがわからなかったので、その辺を聞けばよかったです。
モダンな技術をエンタープライズ開発の現場にインストールした話
エンタープライズ開発の現場で、DDD、CQS、CI/CD を取り入れた話。 自分が行っていることに近い所も多かったので興味深く聴きました。
最初のDDDについてはアーキテクチャ寄りの話が多く、せっかくのドメイン駆動なのでもっと顧客の業務に対してどのように寄り添ってコードに落とし込んだのかということをもっと聴いてみたかった。
次のjOOQにしても、知識の幅を広げるという意味で「Mybatisは使ったことあるからjOOQを採用した。」という考えはわかるのだけども、顧客の業務フローに対してどのようにマッチしているのかみたいなことも聞けたらよかったと思いました。
最後のCI/CDは、Bitbucket Pipelines を使った事例の話でした。Bitbucket Pipelinesは仕事上よく触るし今回のようなECR、ECSと連携する処理も使ったことがあるけど、どうしてもGitHubやGitHub Actionsと比べるとシェアが少ないので情報が少なかったのでこのような事例を発表していたけのがとても良かったです。
ちなみにUIテスト(E2Eテスト)は自動化しようとしたか?は個人的に聞いてみたかったです。(Selenium GridをBitbucket Pipelinesで動かそうとして上手く実行できなかったこともあったので。)
Plug-in Architectures with the Java Module System
最後はAndresさんの英語セッション。セッション名は変わったとの話がありましたがタイトルは忘れてしまいました。
Javaのモジュールシステムのことはあまり知らなかったので聴いてみましたが、やはり英語を聞き取ることが中々に難しかったのと、Layrryの紹介がメインだったこともあり、正直ついていくことができませんでした。
ただ、Layrryに触れてみれば分かることもありそうな感じはしたので、今度機会があれば使ってみたい。
あとQAの時に進行役の杉山さんが「グローバルだと、モジュールシステムを意識して開発していることが多いのか?」みたいなことを質問されていたと思いますが(間違っていたらすみません。)、ちょうど Andres さんが回答した時に家族に声を掛けられて聞けなかったのが悔しかった。
全体として
まずは運営の方々やスタッフの皆様、ありがとうございました。去年の秋は参加できずオンライン参加は今回が初めてでしたが、大きなトラブルもなくセッションを聴くことができました。
ここ最近のCCCは土曜日開催だったと思うのですが、土曜日は家族のイベントが多くオンラインだと集中して見れないので難しかったので、日曜開催だったのは個人的にとても助かりました。
スポンサーブース(Spatial Chat)についてですが、本当なら参加してお話ししたりするべきだとは思ったのですが、セッションを聴いた後の合間の10分の休憩で家のことをやったりしていたので、参加できませんでした。すいません。
次回はオンとオフの両方で参加ができるようになるのかもしれないですが、多分オンラインでの参加になるかなと思います。